
🔔 Array(List)의 가장 큰 특징과 그로 인해 발생하는 장점과 단점에 대해 설명해주세요.
더보기
"Array의 가장 큰 특징과 그로 인한 장점과 단점은 무엇인가요?"
Array는 순차적으로 데이터를 저장하는 구조입니다. 인덱스(index)를 통해 빠른 접근이 가능하다는 장점이 있습니다.
- ✅ 인덱스를 통해 O(1) 시간에 데이터 접근 가능
- ❌ 중간 삽입/삭제 시 전체 요소 이동 → O(n) 성능 저하
"자주 추가/삭제가 발생하는 데이터에 더 적합한 구조는?"
▶ LinkedList가 적합합니다. 삽입/삭제 연산이 빠르기 때문입니다.
🔔 Stack과 Queue, Tree와 Heap의 구조에 대해 설명해주세요.
더보기
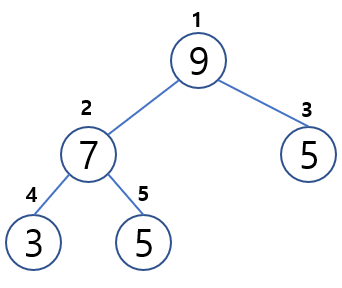
"Stack과 Queue는 어떻게 다르고, Tree와 Heap은 어떤 구조인가요?"
- Stack: LIFO 구조, 가장 나중에 들어온 데이터가 먼저 나감
- Queue: FIFO 구조, 가장 먼저 들어온 데이터가 먼저 나감
- Tree: 비선형 자료구조로 계층적 구조 표현에 적합
- Heap: 완전 이진 트리, 최댓값/최솟값을 빠르게 찾기 위한 구조
"Heap과 Binary Search Tree는 무엇이 다른가요?"
▶ Heap은 정렬 목적, BST는 탐색 목적이며 Heap은 항상 완전이진트리 구조를 가집니다.
🔔 Stack과 Queue 실사용 예시는?
더보기
- Stack: 자바의 Stack 메모리 영역 (메소드 호출/종료 시 활용)
- Queue: 운영체제의 스케줄러에서 프로세스 순서를 관리할 때 사용
"Stack이 아닌 Heap 메모리는 어떤 경우에 사용되나요?"
객체, 배열 등 동적으로 할당되는 데이터는 Heap 영역에 저장됩니다.
🔔 Priority Queue(우선순위 큐)에 대해 설명해주세요.
더보기
우선순위 큐는 우선순위가 높은 데이터를 먼저 꺼내기 위해 만들어진 자료구조입니다.
- 일반적으로 Heap 구조로 구현 (O(logN))
"PriorityQueue를 구현할 때 배열보다 Heap이 나은 이유는?"
▶ Heap은 삽입/삭제 시에도 정렬 상태를 유지하며 성능이 우수합니다.
🔔 Array와 ArrayList의 차이점에 대해 설명해주세요.
더보기
- Array: 크기 고정, 빠른 속도 (고정 크기라 메모리 연산 효율적)
- ArrayList: 크기 가변, 삽입/삭제 편리 (내부적으로 배열을 사용하지만 자동 resize)
"ArrayList가 내부적으로 배열을 사용하는데 왜 느릴까요?"
크기 초과 시 새 배열을 생성하고 복사하는 비용이 발생하기 때문입니다.
🔔 Array와 LinkedList의 장/단점에 대해 설명해주세요.
더보기
- Array는 인덱스(index)로 해당 원소(element)에 접근할 수 있어 찾고자 하는 원소의 인덱스 값을 알고 있으면 O(1)에 해당 원소로 접근할 수 있습니다.
- 즉, RandomAccess가 가능해 속도가 빠르다는 장점이 있습니다.
- 하지만 삽입 또는 삭제의 과정에서 각 원소들을 shift 해줘야 하는 비용이 생겨 이 경우 시간 복잡도는 O(n)이 된다는 단점이 있습니다.
- 이 문제점을 해결하기 위한 자료구조가 linkedlist입니다.
- 각각의 원소들은 자기 자신 다음에 어떤 원소인지만을 기억하고 있기 때문에 이 부분만 다른 값으로 바꿔주면 삽입과 삭제를 O(1)로 해결할 수 있습니다.
- 하지만LinkedList는 원하는 위치에 한 번에 접근할 수 없다는 단점이 있습니다.
- 원하는 위치에 삽입을 하고자 하면 원하는 위치를 Search 과정에 있어서 첫번째 원소부터 다 확인해봐야 합니다.
🔔 해시 테이블(Hash Table)과 시간 복잡도에 대해 설명해주세요.
더보기
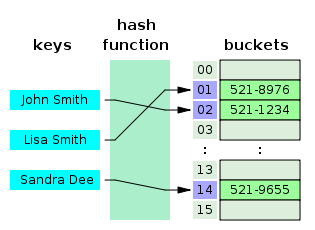
- 해시 테이블은 (Key, Value)로 데이터를 저장하는 자료구조 중 하나로 빠르게 데이터를 검색할 수 있는 자료구조입니다.
- 빠른 검색 속도를 제공하는 이유는 내부적으로 배열(버킷)을 사용하여 데이터를 저장하기 때문입니다.
- 각 Key값은 해시함수에 의해 고유한 index를 가지게 되어 바로 접근할 수 있으므로 평균 O(1)의 시간 복잡도로 데이터를 조회합니다.
- 하지만 index값이 충돌이 발생한 경우 Chanining에 연결된 리스트들까지 검색해야 하므로 O(N)까지 증가할 수 있습니다.
🔔 Hash Map과 Hash Table의 차이점에 대해 설명해주세요.
더보기
- 해시 테이블(Hash Table)
- 병렬 처리를 할 때 (동기화를 고려해야 하는 상황) Thread-safe 하다.
- Null 값을 허용하지 않는다.
- 해시 맵(Hash Map)
- 병렬 처리를 하지 않을 때 (동기화를 고려하지 않는 상황) Thread-safe하지 않는다.
- Null 값을 허용한다.
🔔 BST(Binary Search Tree)와 Binary Tree에 대해 설명해주세요.
더보기
- 이진트리(Binary Tree)는 자식 노드가 최대 두 개인 노드들로 구성된 트리이고,
- 이진 탐색 트리(BST)는 이진 탐색과 연결 리스트를 결합한 자료구조입니다.
- 이진 탐색의 효율적인 탐색 능력을 유지하면서, 빈번한 자료 입력과 삭제가 가능하다는 장점이 있습니다.
- 이진 탐색 트리는 왼쪽 트리의 모든 값은 반드시 부모 노드보다 작아야 하고, 오른쪽 트리의 값은 부모 노드보다 커야 하는 특징이 있습니다.
- 이진 탐색 트리의 탐색 연산은 트리의 높이에 영향을 받아 높이가 h일 때 시간 복잡도는 O(h)이며,
트리의 균형이 한쪽으로 치우쳐진 경우 worst case가 되고 O(n)의 시간 복잡도를 가집니다. - 이런 worst case를 막기 위해 나온 기법이 RBT(Red-Black Tree)입니다.
🔔 RBT(Red-Black Tree)에 대해 설명해주세요.
더보기

- RBT(Red-Black Tree)는 BST를 기반으로 하는 트리 형식 자료구조이며,
RBT는 BST의 삽입, 삭제 연산 과정에서 발생할 수 있는 문제점을 해결하기 위해 만들어졌습니다. - BST를 기반으로 하기 때문에 당연히 BST의 특징을 모두 갖습니다.
- 노드의 child가 없을 경우 child를 가리키는 포인터는 NIL 값을 저장합니다.
- 이러한 NIL들을 leaf node로 간주합니다.
- 모든 노드를 빨간색 또는 검은색으로 색칠하며, 연결된 노드들은 색이 중복되지 않습니다.
'취준 > 면접' 카테고리의 다른 글
| [면접 준비] - 벡엔드 (0) | 2024.05.20 |
|---|---|
| [면접 준비] - 운영체제 (0) | 2024.05.20 |
| [면접 준비] - 네트워크 (0) | 2024.05.20 |
| [면접 준비] - 데이터베이스 (0) | 2024.05.20 |
| [면접 준비] - 자바 (0) | 2024.05.20 |